API#
Initializing Environments#
Initializing environments is very easy in Gym and can be done via:
import gym
env = gym.make('CartPole-v0')
Interacting with the Environment#
Gym implements the classic “agent-environment loop”:
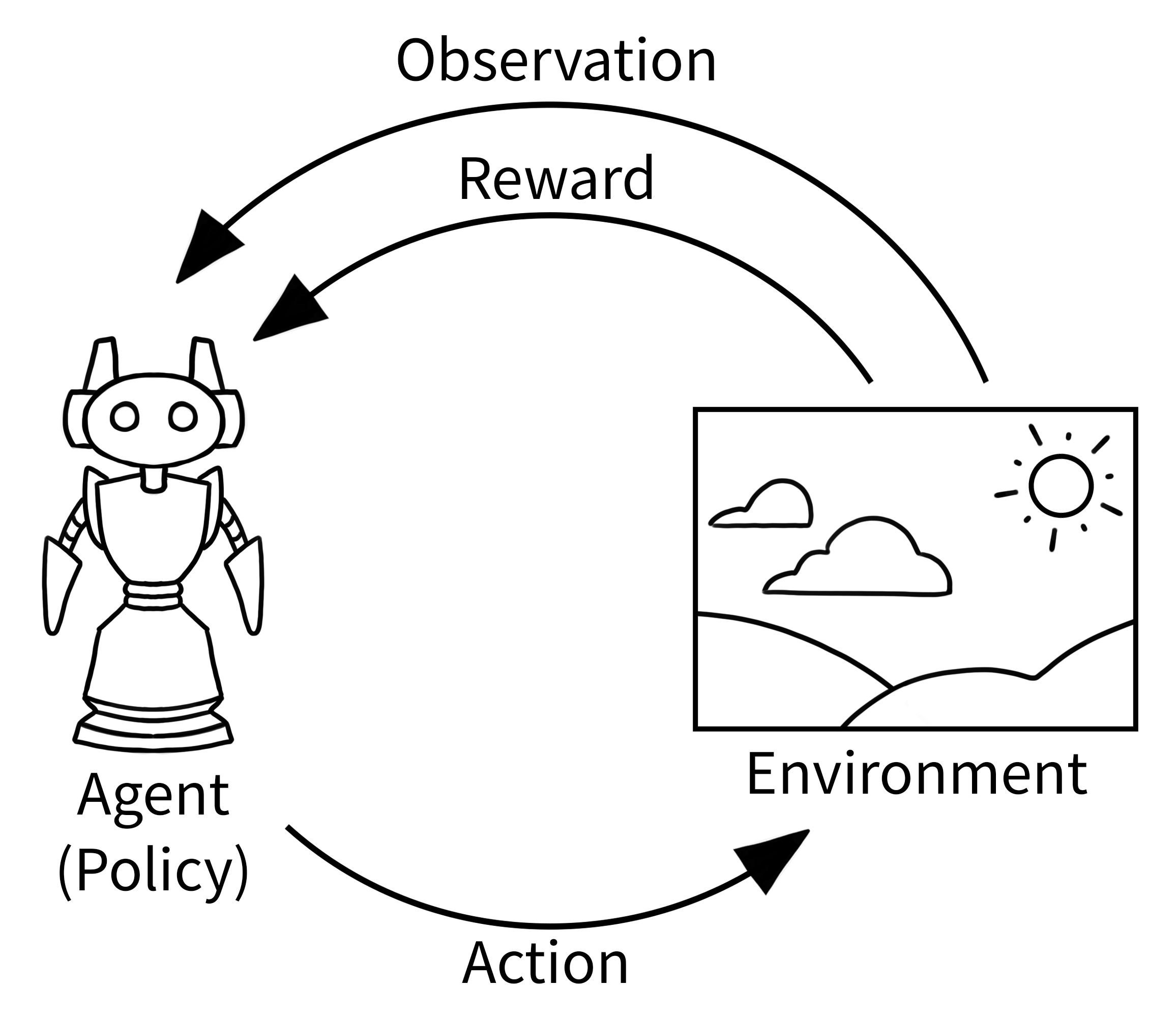
The agent performs some actions in the environment (usually by passing some control inputs to the environment, e.g. torque inputs of motors) and observes how the environment’s state changes. One such action-observation exchange is referred to as a timestep.
The goal in RL is to manipulate the environment in some specific way. For instance, we want the agent to navigate a robot to a specific point in space. If it succeeds in doing this (or makes some progress towards that goal), it will receive a positive reward alongside the observation for this timestep. The reward may also be negative or 0, if the agent did not yet succeed (or did not make any progress). The agent will then be trained to maximize the reward it accumulates over many timesteps.
After some timesteps, the environment may enter a terminal state. For instance, the robot may have crashed, or the agent may have succeeded in completing a task. In that case, we want to reset the environment to a new initial state. The environment issues a terminated signal to the agent if it enters such a terminal state. Sometimes we also want to end the episode after a fixed number of timesteps, in this case, the environment issues a truncated signal. This is a new change in API. Earlier a common done signal was issued for an episode ending via any means. This is now changed in favour of issuing two signals - terminated and truncated.
Let’s see what the agent-environment loop looks like in Gym.
This example will run an instance of LunarLander-v2 environment for 1000 timesteps, rendering the environment at each step. You should see a window pop up rendering the environment
import gym
env = gym.make("LunarLander-v2")
env.action_space.seed(42)
observation, info = env.reset(seed=42, return_info=True)
for _ in range(1000):
env.render()
observation, reward, terminated, truncated, info = env.step(env.action_space.sample())
if terminated or truncated:
observation, info = env.reset(return_info=True)
env.close()
The output should look something like this

Every environment specifies the format of valid actions by providing an env.action_space attribute. Similarly,
the format of valid observations is specified by env.observation_space.
In the example above we sampled random actions via env.action_space.sample(). Note that we need to seed the action space separately from the
environment to ensure reproducible samples.
Change in env.step API#
Previously, the step method returned only one boolean - done. This is being deprecated in favour of returning two booleans terminated and truncated.
Environment termination can happen due to any number of reasons inherent to the environment eg. task completition, failure etc. This is distinctly different from an episode of the environment ending due to a user-set time-limit, referred to as ‘truncation’.
terminated signal is set to True when the core environment terminates inherently because of task completition, failure etc.
truncated signal is set to True when the episode ends specifically because of a time-limit not inherent to the environment.
It is possible for terminated=True and truncated=True to occur at the same time when termination and truncation occur at the same step.
Motivation#
This is done to remove the ambiguity in the done signal. done=True does not distinguish between the environment terminating and the episode truncating. This problem was avoided previously by setting info['TimeLimit.truncated'] in case of a timelimit through the TimeLimit wrapper. However, this forces the truncation to happen only through a wrapper, and does not accomodate environments which truncate in the core environment.
The main reason we need to distinguish between these two signals is the implications in implementing the Temporal Difference update, where the reward along with the value of the next state(s) are used to update the value of the current state. At terminal states, there is no contribution from the value of the next state(s) and we only consider the value as a function of the reward at that state. However, this is not true when we forcibly truncate the episode. Time-limits are often set during training to diversify experience, but the goal of the agent is not to maximize reward over this time period. The done signal is often used to control whether the value of the next state
is used for backup.
vf_target = rew + gamma * (1-done)* vf(next_obs)
However, this leads to the next state backup being ignored during truncations as well which is incorrect. (See link for details)
Instead, using explicit terminated and truncated signals resolves this problem.
# vf_target = rew + gamma * (1-done)* vf(next_obs) # wrong
vf_target = rew + gamma * (1-terminated)* vf(next_obs) # correct
Backward compatibility#
Gym will retain support for the old API till v1.0 for ease of transition.
Users can toggle the old API through make by setting return_two_dones=False.
env = gym.make("CartPole-v1", return_two_dones=False)
This can also be done explicitly through a wrapper:
from gym.wrappers import StepCompatibility
env = StepCompatibility(CustomEnv(), return_two_dones=False)
For more details see the wrappers section.
Standard methods#
Stepping#
- gym.Env.step(self, action: gym.core.ActType) Tuple[gym.core.ObsType, float, bool, dict]#
Run one timestep of the environment’s dynamics. When end of episode is reached, you are responsible for calling reset() to reset this environment’s state.
Accepts an action and returns a tuple (observation, reward, done, info).
- Parameters
action (object) – an action provided by the agent
- Returns
observation (object) – agent’s observation of the current environment
reward (float) – amount of reward returned after previous action
done (bool) – whether the episode has ended, in which case further step() calls will return undefined results
info (dict) – contains auxiliary diagnostic information (helpful for debugging, logging, and sometimes learning)
Resetting#
- gym.Env.reset(self, *, seed: Optional[int] = None, return_info: bool = False, options: Optional[dict] = None) Union[gym.core.ObsType, tuple[ObsType, dict]]#
Resets the environment to an initial state and returns an initial observation.
This method should also reset the environment’s random number generator(s) if seed is an integer or if the environment has not yet initialized a random number generator. If the environment already has a random number generator and reset is called with seed=None, the RNG should not be reset. Moreover, reset should (in the typical use case) be called with an integer seed right after initialization and then never again.
- Returns
observation (object) – the initial observation.
info (optional dictionary) – a dictionary containing extra information, this is only returned if return_info is set to true
Rendering#
- gym.Env.render(self, mode='human')#
Renders the environment.
The set of supported modes varies per environment. (And some third-party environments may not support rendering at all.) By convention, if mode is:
human: render to the current display or terminal and return nothing. Usually for human consumption.
rgb_array: Return an numpy.ndarray with shape (x, y, 3), representing RGB values for an x-by-y pixel image, suitable for turning into a video.
ansi: Return a string (str) or StringIO.StringIO containing a terminal-style text representation. The text can include newlines and ANSI escape sequences (e.g. for colors).
Note
- Make sure that your class’s metadata ‘render_modes’ key includes
the list of supported modes. It’s recommended to call super() in implementations to use the functionality of this method.
- Parameters
mode (str) – the mode to render with
Example:
- class MyEnv(Env):
metadata = {‘render_modes’: [‘human’, ‘rgb_array’]}
- def render(self, mode=’human’):
- if mode == ‘rgb_array’:
return np.array(…) # return RGB frame suitable for video
- elif mode == ‘human’:
… # pop up a window and render
- else:
super(MyEnv, self).render(mode=mode) # just raise an exception
Additional Environment API#
Attributes#
- Env.action_space: spaces.Space[ActType]#
This attribute gives the format of valid actions. It is of datatype Space provided by Gym. For example, if the action space is of type Discrete and gives the value Discrete(2), this means there are two valid discrete actions: 0 & 1.
>>> env.action_space Discrete(2) >>> env.observation_space Box(-3.4028234663852886e+38, 3.4028234663852886e+38, (4,), float32)
- Env.observation_space: spaces.Space[ObsType]#
this attribute gives the format of valid observations. It is of datatype
Spaceprovided by Gym. For example, if the observation space is of typeBoxand the shape of the object is(4,), this denotes a valid observation will be an array of 4 numbers. We can check the box bounds as well with attributes.>>> env.observation_space.high array([4.8000002e+00, 3.4028235e+38, 4.1887903e-01, 3.4028235e+38], dtype=float32) >>> env.observation_space.low array([-4.8000002e+00, -3.4028235e+38, -4.1887903e-01, -3.4028235e+38], dtype=float32)
- Env.reward_range = (-inf, inf)#
returns a tuple corresponding to min and max possible rewards. Default range is set to
[-inf,+inf]. You can set it if you want a narrower range .
Methods#
- gym.Env.close(self)#
Override close in your subclass to perform any necessary cleanup.
Environments will automatically close() themselves when garbage collected or when the program exits.
- gym.Env.seed(self, seed=None)#
Sets the seed for this env’s random number generator(s).
Note
Some environments use multiple pseudorandom number generators. We want to capture all such seeds used in order to ensure that there aren’t accidental correlations between multiple generators.
- Returns
list<bigint> – Returns the list of seeds used in this env’s random number generators. The first value in the list should be the “main” seed, or the value which a reproducer should pass to ‘seed’. Often, the main seed equals the provided ‘seed’, but this won’t be true if seed=None, for example.
Checking API-Conformity#
If you have implemented a custom environment and would like to perform a sanity check to make sure that it conforms to the API, you can run:
>>> from gym.utils.env_checker import check_env
>>> check_env(env)
This function will throw an exception if it seems like your environment does not follow the Gym API. It will also produce
warnings if it looks like you made a mistake or do not follow a best practice (e.g. if observation_space looks like
an image but does not have the right dtype). Warnings can be turned off by passing warn=False. By default, check_env will
not check the render method. To change this behavior, you can pass skip_render_check=False.
After running
check_envon an environment, you should not reuse the instance that was checked, as it may have already been closed!
Spaces#
Spaces are usually used to specify the format of valid actions and observations.
Every environment should have the attributes action_space and observation_space, both of which should be instances
of classes that inherit from Space.
There are multiple Space types available in Gym:
Box: describes an n-dimensional continuous space. It’s a bounded space where we can define the upper and lower limits which describe the valid values our observations can take.Discrete: describes a discrete space where {0, 1, …, n-1} are the possible values our observation or action can take. Values can be shifted to {a, a+1, …, a+n-1} using an optional argument.Dict: represents a dictionary of simple spaces.Tuple: represents a tuple of simple spaces.MultiBinary: creates a n-shape binary space. Argument n can be a number or alistof numbers.MultiDiscrete: consists of a series ofDiscreteaction spaces with a different number of actions in each element.
>>> from gym.spaces import Box, Discrete, Dict, Tuple, MultiBinary, MultiDiscrete
>>>
>>> observation_space = Box(low=-1.0, high=2.0, shape=(3,), dtype=np.float32)
>>> observation_space.sample()
[ 1.6952509 -0.4399011 -0.7981693]
>>>
>>> observation_space = Discrete(4)
>>> observation_space.sample()
1
>>>
>>> observation_space = Discrete(5, start=-2)
>>> observation_space.sample()
-2
>>>
>>> observation_space = Dict({"position": Discrete(2), "velocity": Discrete(3)})
>>> observation_space.sample()
OrderedDict([('position', 0), ('velocity', 1)])
>>>
>>> observation_space = Tuple((Discrete(2), Discrete(3)))
>>> observation_space.sample()
(1, 2)
>>>
>>> observation_space = MultiBinary(5)
>>> observation_space.sample()
[1 1 1 0 1]
>>>
>>> observation_space = MultiDiscrete([ 5, 2, 2 ])
>>> observation_space.sample()
[3 0 0]
Wrappers#
Wrappers are a convenient way to modify an existing environment without having to alter the underlying code directly.
Using wrappers will allow you to avoid a lot of boilerplate code and make your environment more modular. Wrappers can
also be chained to combine their effects. Most environments that are generated via gym.make will already be wrapped by default.
In order to wrap an environment, you must first initialize a base environment. Then you can pass this environment along with (possibly optional) parameters to the wrapper’s constructor:
>>> import gym
>>> from gym.wrappers import RescaleAction
>>> base_env = gym.make("BipedalWalker-v3")
>>> base_env.action_space
Box([-1. -1. -1. -1.], [1. 1. 1. 1.], (4,), float32)
>>> wrapped_env = RescaleAction(base_env, min_action=0, max_action=1)
>>> wrapped_env.action_space
Box([0. 0. 0. 0.], [1. 1. 1. 1.], (4,), float32)
There are three very common things you might want a wrapper to do:
Transform actions before applying them to the base environment
Transform observations that are returned by the base environment
Transform rewards that are returned by the base environment
Such wrappers can be easily implemented by inheriting from ActionWrapper, ObservationWrapper, or RewardWrapper and implementing the
respective transformation.
However, sometimes you might need to implement a wrapper that does some more complicated modifications (e.g. modify the
reward based on data in info). Such wrappers
can be implemented by inheriting from Wrapper.
Gym already provides many commonly used wrappers for you. Some examples:
TimeLimit: Issue a truncated signal if a maximum number of timesteps has been exceeded.ClipAction: Clip the action such that it lies in the action space (of type Box).RescaleAction: Rescale actions to lie in a specified intervalTimeAwareObservation: Add information about the index of timestep to observation. In some cases helpful to ensure that transitions are Markov.
If you have a wrapped environment, and you want to get the unwrapped environment underneath all of the layers of wrappers (so that you can manually call a function or change some underlying aspect of the environment), you can use the .unwrapped attribute. If the environment is already a base environment, the .unwrapped attribute will just return itself.
>>> wrapped_env
<RescaleAction<TimeLimit<BipedalWalker<BipedalWalker-v3>>>>
>>> wrapped_env.unwrapped
<gym.envs.box2d.bipedal_walker.BipedalWalker object at 0x7f87d70712d0>
Playing within an environment#
You can also play the environment using your keyboard using the play function in gym.utils.play.
from gym.utils.play import play
play(gym.make('Pong-v0'))
This opens a window of the environment and allows you to control the agent using your keyboard.
Playing using the keyboard requires a key-action map. This map should be a dict: tuple(int) -> int or None, which maps the keys pressed to action performed.
For example, if pressing the keys w and space at the same time is supposed to perform action 2, then the key_to_action dict should look like:
{
# ...
(ord('w'), ord(' ')): 2,
# ...
}
As a more complete example, let’s say we wish to play with CartPole-v0 using our left and right arrow keys. The code would be as follow:
import gym
import pygame
from gym.utils.play import play
mapping = {(pygame.K_LEFT,): 0, (pygame.K_RIGHT,): 1}
play(gym.make("CartPole-v0"), keys_to_action=mapping)
where we obtain the corresponding key ID constants from pygame. If the key_to_action argument is not specified, then the default key_to_action mapping for that env is used, if provided.
Furthermore, you wish to plot real time statistics as you play, you can use gym.utils.play.PlayPlot. Here’s some sample code for plotting the reward for last 5 second of gameplay:
def callback(obs_t, obs_tp1, action, rew, terminated, truncated, info):
return [rew,]
plotter = PlayPlot(callback, 30 * 5, ["reward"])
env = gym.make("Pong-v0")
play(env, callback=plotter.callback)